Crawlers
Pick The Right Crawler For You!
Explore Now
Industry-Specific
Solutions
 E-commerce Data Scraping
E-commerce Data Scraping
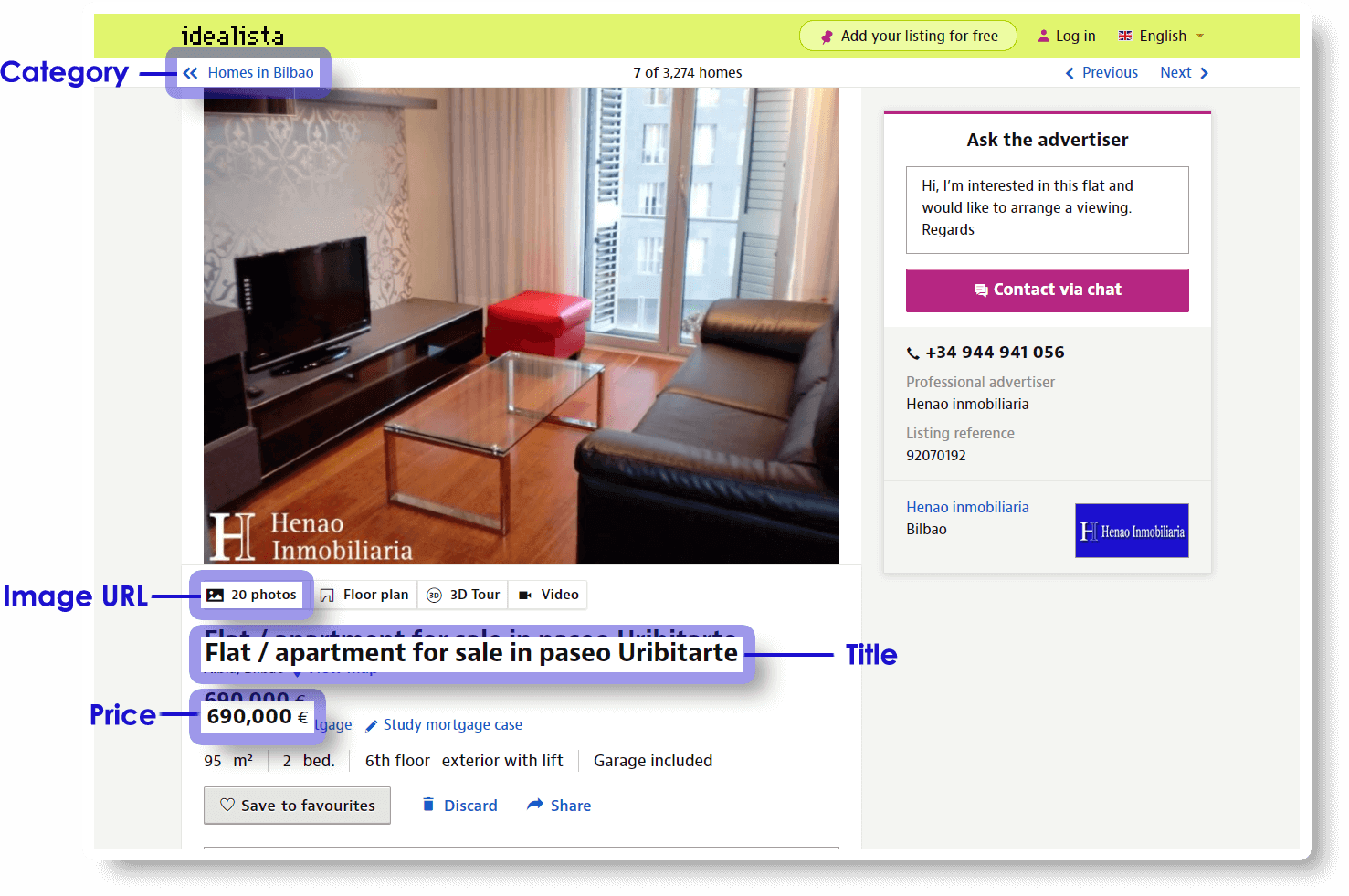
 Real Estate & Property Data Scraping
Real Estate & Property Data Scraping
 Healthcare & Medical Data Scraping
Healthcare & Medical Data Scraping
 Food Delivery Data Scraping
Food Delivery Data Scraping
 Travel & Hotel Data Scraping
Travel & Hotel Data Scraping
 OTT Streaming Data Scraping
OTT Streaming Data Scraping
 Automotive Data Scraping
Automotive Data Scraping
 Job Listings & Recruitment
Job Listings & Recruitment
 Business Directory Data Scraping
Business Directory Data Scraping
 News & Article Data Scraping
News & Article Data Scraping
 Social Media Data Scraping
Social Media Data Scraping
 Government Website Data Scraping
Government Website Data Scraping
Specialized Data Extraction




Quick Commerce & FMCG Data Extraction
Extract real-time Quick Commerce & FMCG data to boost pricing, trends, and sales insights.
Vacation Rental Data Extraction
Extract accurate Vacation Rental data with ease to track pricing, listings, and trends.
Restaurant Data Extraction
Get detailed Restaurant data like menus, ratings, and contacts with powerful extraction.
Event & Meeting Data Extraction
Efficiently extract Event and Meeting data for streamlined planning and insights.
Boost Your Business with targeted Data Extraction!
View MoreAI-driven web scraping for accurate, automated data extraction—saving time & boosting insights.
Extract data tailored to your unique business needs with custom solutions.
Scrape data from mobile apps for detailed insights and competitor analysis.
Access structured web data effortlessly using our smart Web Scraping API solution.
Develop scalable web crawlers for fast, automated, and efficient data collection.
Extract real-time data from dynamic websites for timely insights and market advantage.
Track competitor pricing trends and stay ahead with smart Price Monitoring Services.
Track and analyze your brand's online presence to enhance reputation and drive growth.
Accurately match identical products across platforms to boost sales and visibility.
Transform your data into insightful visuals for better decision-making and analysis.
Extract and analyze online data with powerful Web Data Mining for smarter decisions and competitive growth.
Understand customer opinions and feedback with accurate Sentiment Analysis solution.
Monitor product visibility, pricing, and performance across online stores with advanced Digital Shelf Analytics solutions.
Boost data accuracy and efficiency with machine learning-based web scraping for smart automation.
High-quality AI training datasets for accurate models, automation, and smarter insights.